
Fable's outage turned model routing into strategy
The AI Daily Brief argues that Fable 5's disappearance is pushing AI teams toward routing architectures: open models, specialist coding models, frontier advisors, and model panels used together instead of one expensive default model.

The AI Daily Brief's June 18 episode is less a model news roundup than a strategy memo for the week after Fable 5 vanished. NLW's central claim is blunt: if frontier access can be interrupted by policy and frontier inference keeps getting more expensive, the winning AI stack is no longer "pick the best model." It is route each task to the cheapest model that can do it well. The episode's title says "models trying to replace Fable," but its stronger argument is that no single replacement is likely to be enough 1.
コンテンツカードを読み込んでいます…
The shock was access, not just capability
The episode starts with geopolitics because the Fable problem is not framed as a normal product outage. At the G7 meeting in France, AI executives including Sam Altman, Demis Hassabis, Dario Amodei, Arthur Mensch, and Aidan Gomez were in the room with heads of state. NLW reads that as evidence that frontier model access has become a diplomatic issue, not just a vendor relationship 1.
The most important detail is not the familiar language about AI safety standards. It is that allied governments still could not get clear access guarantees. The episode says UK Prime Minister Keir Starmer asked for a carve-out from the export control restrictions for British nationals and companies and was denied 1. That changes the risk model for any company building around a closed frontier model: the model can be technically excellent and still fail the procurement test if access depends on politics.
NLW also puts Europe's infrastructure gap in numerical terms. The European Commission's AI gigafactory plan commits 20 billion euros and targets about 100,000 GPUs; the episode contrasts that with U.S. hyperscalers spending roughly three times that amount every month on AI data centers 1. The point is not that Europe cannot build AI capacity. It is that sovereignty talk without compute quickly becomes dependency by another name.
The replacement market is a bundle, not a crown
The most useful section of the episode is its tour of the alternatives. NLW does not treat them as a neat leaderboard where one winner replaces Fable. Each candidate solves a different part of the problem: lower cost, local control, specialized coding performance, or automatic routing.
| Candidate discussed in the episode | What it is supposed to solve | The catch |
|---|---|---|
| Kimi K2.7 Code | Open-source coding performance with reported gains over Kimi 2.6, including lower reasoning-token usage. Episode | NLW says early users were not uniformly impressed, and Agent Arena still placed it 19th overall. |
| Vive Thinker 3B | A very small reasoning-tuned model that can run on local hardware. Episode | It appears tuned for reasoning rather than broad knowledge, so it points to a system design idea more than an enterprise-ready replacement. |
| ZAI GLM 5.2 | A Chinese open model drawing attention for benchmark wins, design tasks, speed, and cost. Episode | The episode flags possible benchmark-maxing and unresolved questions about distillation. |
| Cursor Composer 2.5 | A coding model built on a Kimi foundation and post-trained for software tasks. Episode | Some engineers see strong value, but others report unwanted file changes and weaker agentic-coding results after benchmark updates. |
| OpenRouter Fusion | A compound model that fans a prompt out to a panel of models, then judges and synthesizes the answers. Episode | It shifts trust from one model to a routing-and-judging layer, which becomes its own critical dependency. |
| Harvey's worker-advisor setup | An open-weight worker model handles routine work, then delegates hard tasks to a closed frontier advisor. Episode | This is a higher-complexity architecture, not a simple API swap. |
That table is the episode's real thesis in miniature. Open models matter, but not because every enterprise will immediately run GLM or Kimi everywhere. They matter because they give builders more degrees of freedom. A system can use a local model for cheap routine work, a coding specialist for narrow software tasks, a frontier model for high-stakes judgment, and a panel when independent reasoning paths are useful.
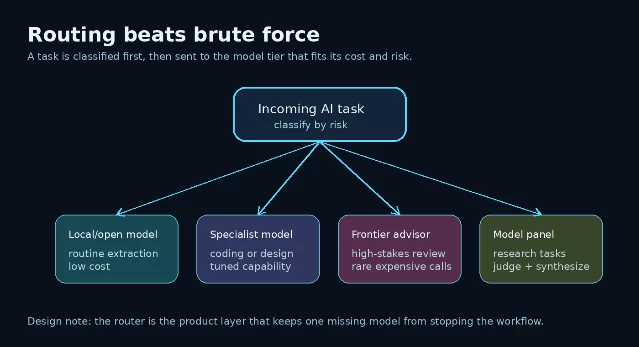
Cost pressure made the idea inevitable
The Fable outage adds urgency, but NLW argues that enterprises were already moving toward model pluralism because agentic workloads changed the economics. As agents run longer, spawn sub-agents, and execute more autonomous loops, token bills rise in ways that normal chat usage did not prepare teams for 1.
That is why the Composer comparison lands. The episode quotes engineer Yasser's rough tradeoff: Composer 2.5 scored 65% for $1, while Fable scored 70% for $12. His question was simple: why pay 12 times more for a five-point gain? 1 The exact benchmark is less important than the buying logic. Once a model is good enough for a class of tasks, marginal quality has to justify marginal cost.
The Harvey example makes the argument more concrete. In the episode's telling, Harvey worked with Fireworks on a worker-advisor architecture: an open-weight GLM 5.1 worker delegates high-stakes or complex tasks to Opus 4.7. The combination was cheaper than using Opus 4.7 alone and performed better in the test NLW describes 1. That is the move from model selection to workflow design.
The takeaway: route before you replace
The episode's cleanest line comes near the end: "The insight isn't that open source beat frontier, it's that smart routing beat brute force" 1. That should be the sentence operators remember.
For practitioners, the implication is practical. Do not start with the question "What is our Fable replacement?" Start with an inventory of tasks. Which tasks require top-tier reasoning? Which only require extraction, classification, code edits, or first-pass drafting? Which must run locally for access, privacy, or latency reasons? Which can tolerate a cheaper model if a stronger model reviews the output?
The episode is careful, even if the market chatter it summarizes is not. It does not prove that Chinese open models are now generally better than U.S. frontier models. It does not prove that every enterprise should move off closed APIs. It argues that the old default has become fragile: using the strongest available model for everything is expensive when it works and brittle when access changes.
Fable may return. If it does, the lesson still holds. A post-Fable AI stack should be built less like a throne and more like dispatch software: send the work to the model that fits the job, watch the cost, and keep enough optionality that one missing model does not stop the whole machine.
このコンテンツについて、さらに観点や背景を補足しましょう。