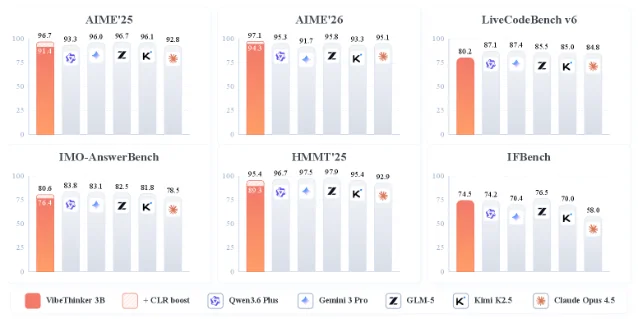
VibeThinker-3B self-reported benchmark scores
All scores from arXiv:2606.16140; zero independent third-party reproductions published as of June 19, 2026

WeiboAI's VibeThinker-3B claims frontier-level math and code reasoning on a consumer GPU — all benchmarks self-reported, no independent verification yet, but the architecture hypothesis is the real story for PMs.

uv script is — the most common Python package manager — something no LLM has gotten wrong in at least a year. 2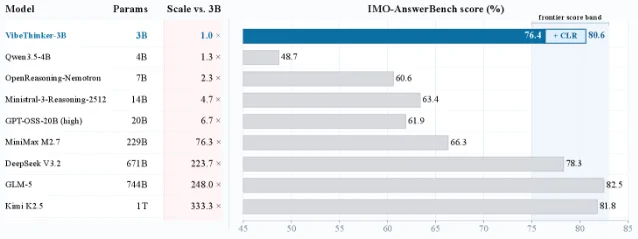
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.