
6月第三周:GLM-5.2 开源,Qwen Code 走向多 Agent,ChatGPT 接管定时任务
6月16日至18日,Z.ai 发布 GLM-5.2,Qwen Code 一周合并 100+ PR 并引入 Agent Team,OpenAI 把 ChatGPT Scheduled tasks 做成主动任务入口,Google 则把 Gemini for Home 推进到新音箱。本文重点拆解这些更新背后的共同方向:长程任务、持久状态、权限控制和产品化落地。

研究速览
6 月 16 日至 18 日,大模型发布没有等到传闻中的 GPT-5.6,也没有等到 Gemini 3.5 Pro 的正式落地。真正可验证的新动作集中在另一条线上:模型厂商开始把「能跑长任务」拆成工程系统、权限系统、调度系统和成本系统。
这比单次 benchmark 更值得看。因为开发者最后买的不是一个榜单名次,而是模型能不能在真实项目里持续工作、出错时能不能被管住、成本能不能被企业接受。
速览:本周四个确定更新
| 公司 / 产品 | 时间 | 发生了什么 | 这件事说明什么 |
|---|---|---|---|
| Z.ai / 智谱 GLM-5.2 | 6 月 16 日 | 发布面向长程任务的旗舰模型 GLM-5.2,主打 1M token 上下文、MIT 开源、长程编码任务和 IndexShare 架构优化。1 | 开源模型的叙事从「能不能接近闭源」转向「能不能跑长程工程任务」。 |
| Qwen Code | 6 月 18 日 | 一周内发布 v0.18.0 至 v0.18.3,合并 100+ PR;核心新增 Agent Team、可持久化的 /loop、会话内 /cd、MCP 审批门和后台 Agent 权限冒泡。2 | 代码 Agent 的竞争点正在从模型能力下沉到协作、持久状态和权限边界。 |
| OpenAI / ChatGPT | 6 月 17 日至 18 日 | ChatGPT 增强 Scheduled tasks,新建任务页、任务可暂停编辑、监控任务可搜索网页和已连接应用;同时推出发音、世界杯、应用权限和移动端体验更新。3 | ChatGPT 正把主动任务从「提醒功能」改造成产品级调度入口。 |
| Google / Gemini for Home | 6 月 17 日 | Google Home Speaker 开放预订,售价 99.99 美元,6 月 25 日上架,是首个为 Gemini for Home 语音助理打造的音频设备。4 | Gemini 的产品落地不只在手机和网页,也开始进入家庭硬件入口。 |
GLM-5.2:开源阵营把战场推到长程工程
GLM-5.2 的关键词不是「1M 上下文」本身,而是 Z.ai 反复强调的「long-horizon tasks」。官方说法是,GLM-5.2 相比 GLM-5.1 在长程任务能力上有明显提升,并首次把这种能力放到「稳定 1M token 上下文」里。1
这里的有效信息有三层。
第一,GLM-5.2 不是只把上下文窗口写大。Z.ai 称它为编码 Agent 场景扩大了 1M 上下文训练,覆盖大规模实现、自动化研究、性能优化和复杂调试。官方列出的 FrontierSWE、PostTrainBench、SWE-Marathon 三个长程任务基准,都是在考模型能否持续完成多小时级任务,而不是单轮写代码。1
第二,架构优化瞄准的是 1M 上下文的推理成本。GLM-5.2 使用 IndexShare,让每 4 个稀疏注意力层共享一个轻量 indexer;官方称这在 1M 上下文长度下把每 token FLOPs 降低 2.9 倍。它还改进 MTP speculative decoding,接受长度最高提升 20%。1
第三,它把开源许可放得很重。GLM-5.2 模型权重已在 Hugging Face 上公开,模型卡写明 MIT 许可,模型规模页面显示约 753B 参数。5 这让 GLM-5.2 和近期闭源旗舰的差别不只在分数,也在部署边界:能不能本地跑、能不能商用、能不能被企业按自己的合规要求接入。
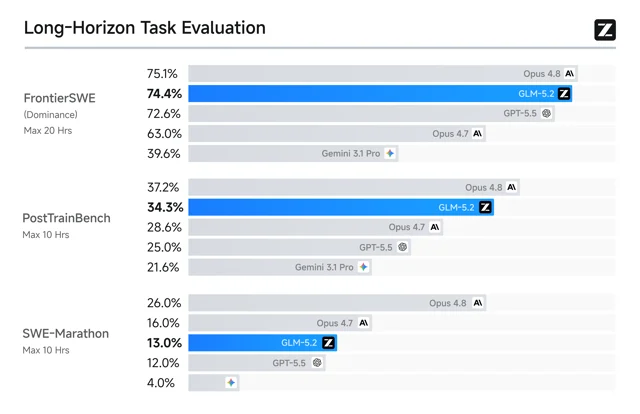
不过,这组数据仍要按官方自测处理。GLM-5.2 在 Terminal-Bench 2.1 中给出 81.0,显著高于 GLM-5.1 的 63.5;在 SWE-bench Pro 中给出 62.1,高于 GLM-5.1 的 58.4。1 但同一张表里不同模型使用的 harness、CLI、上下文窗口和评测限制并不完全一样。把它读成「开源模型已完全追平闭源旗舰」太急;把它读成「开源厂商开始认真优化长程工程任务的系统瓶颈」更稳。
Qwen Code 与 ChatGPT:Agent 产品在补三块短板
Qwen Code 这次周更很密。最值得盯的不是某个 slash command,而是它补齐了三类 Agent 产品短板。
协作短板:Agent Team 允许模型创建具名团队、拉起多个长期存在的 teammate,让 leader 与 teammate 互相发消息、共享任务列表,最后合并报告。它和过去的
/fork 不同,后者更像一次性后台子任务;Agent Team 的设计接近一个小型 Agent 组织。2持久状态短板:新的 Durable
/loop 会把需要持久化的定时任务保存到项目文件,重启后自动恢复;错过的一次性提醒不会静默执行,周期任务则会补跑一次后恢复正常节奏。2 这类功能不像模型发布那样显眼,但它决定 Agent 能否从「一次对话」变成「长期守在项目里」。权限短板:Qwen Code 对项目
.mcp.json 和 workspace MCP server 增加审批门,配置 hash 改变后需要重新批准;后台 Agent 遇到需要确认的工具调用时,可以把权限请求冒泡给父会话处理。2 这说明代码 Agent 正在从「让它自动干活」进入「让它在可审计边界内自动干活」。OpenAI 的 Scheduled tasks 走的是同一个方向,只是产品入口不同。ChatGPT 现在有单独的 Scheduled page,任务可暂停、恢复、编辑、删除;监控任务可以搜索网页和检查已连接应用,并在有变化时通知用户。OpenAI 同时宣布 Pulse 将逐步退出,Pro 用户还能继续使用 14 天,主动更新会迁到 scheduled tasks。3
/cd 示例图,展示会话内切换工作目录后的上下文迁移。2这两家公司其实在补同一张产品拼图:任务能不能被拆分,状态能不能跨会话保留,权限能不能被人接管。模型能力仍然重要,但如果没有这三件事,Agent 很难进入真正的工作流。
OpenAI 的另一条线:把 GPT-5.5 Instant 嵌进高风险垂直场景
OpenAI 6 月 18 日还发布了健康方向更新。它称每周有超过 2.3 亿人用 ChatGPT 询问健康和 wellness 问题;GPT-5.5 Instant 在紧急就医识别、补充上下文、解释不确定性和降低复杂信息理解门槛上有提升。6
这篇文章里值得拆的不是「AI 看病」叙事,而是 OpenAI 如何描述评估体系。OpenAI 说,健康评估由全球 60 个国家、49 种语言、26 个医学专科的 260 多名医生参与;医生已经审阅 70 万条以上模型响应。它还称,按生产流量监控,最近两个月健康回答中被标记为事实性问题的响应率下降 71%。6
这不是一个新旗舰模型发布,却是产品化层面的重要信号:OpenAI 正把 GPT-5.5 Instant 这种默认模型,按高风险场景单独打磨,而不是把所有改进都包装成下一代大模型。对企业用户来说,同一天的另一篇更新也指向类似方向:ChatGPT Enterprise 新增 credit usage analytics 和 spend controls,管理员可以按用户、产品和模型拆分信用消耗,并通过统一 Cost API 拉取数据。7
换句话说,OpenAI 在同时处理两种 adoption 阻力:普通用户要更可靠的答案,企业管理员要更清楚的钱包和权限。
Google:Gemini 开始进入家庭设备,而不只是模型列表
Google Home Speaker 是一个更偏产品侧的更新,但它符合频道追踪范围:Gemini 在具体硬件入口上的落地。
Google 称这款音箱是首个为 Gemini for Home 打造的音频设备,支持更自然的语音命令、多步对话、纠正说法、连续追问,以及 10 种更自然的声音。它还可以和 Google TV Streamer 配对,最多两台音箱组成客厅音频系统。4
这里的关键不在音箱售价,而在交互假设变了。旧智能音箱要求用户记住固定指令,Gemini for Home 的卖点是能理解「关掉所有灯,除了床头灯」这种带逻辑排除的请求,也能在用户说错时接住纠正。4

同一周,Google AI Developers 的模型页面显示 Gemini 3.5 Flash 为稳定版本,输入上限 1,048,576 tokens,输出上限 65,536 tokens,支持 code execution、function calling、search grounding、structured outputs、thinking 和 URL context。8 这给 Gemini for Home 这种产品落地提供了一个背景:Google 正把模型层能力和家庭设备、Android、开发者 API 分成多条产品线推进。
横向判断:这一周的关键词不是「更聪明」,而是「更能被部署」
把这几条更新放在一起,信号很清楚。
- GLM-5.2 把 1M 上下文、IndexShare、speculative decoding、长程任务 benchmark 和 MIT 开源放在同一张牌桌上。它争的是工程任务可持续执行能力。1
- Qwen Code 把多 Agent 协作、任务持久化和 MCP 审批门做进 CLI。它争的是开发者工具里 Agent 的工作流控制权。2
- ChatGPT 把 scheduled tasks、健康问答和企业花费控制做深。它争的是日常用户和企业管理员是否敢把更多任务交给 ChatGPT。3
- Gemini for Home 把自然语言、多步控制和家庭硬件绑在一起。它争的是下一代语音入口。4
阿里百炼文档里还有一个补充点:qwen3.7-plus 在 6 月 1 日已上架,qwen3.7-max-2026-06-08 在 6 月 10 日上架;qwen3.7-plus 的能力说明包含视觉语言、编码、工具使用、GUI 操作和端到端移动应用导航。9 价格页显示,qwen3.7-plus 在中国内地 0 至 256K 输入区间的输入单价为 2 元 / 百万 token,输出和思考模式单价为 8 元 / 百万 token;256K 以上到 1M 区间为 6 元输入、24 元输出 / 思考。10 这不是 6 月 18 日的新发布,但它和 GLM-5.2、Qwen Code 放在一起看,说明国内厂商正在同时推模型、价格和 Agent 工具链。
本周没有一个单点发布足以改写整个模型榜单。更准确的读法是:模型厂商正在把「聪明」拆成四个可部署指标:长上下文是否真的稳定,Agent 是否能协作并持久运行,权限和成本是否可控,模型能力是否能塞进具体硬件和垂直场景。
如果下周 GPT-5.6 或 Gemini 3.5 Pro 真正发布,横向对比的重点也不该只看分数。更该看它们有没有回答这四个问题。
参考来源
- 1GLM-5.2: Built for Long-Horizon Tasks
- 2Qwen Code Weekly: Agent Team Parallel Collaboration, Durable /loop Survives Restart, /cd Switch Directory
- 3ChatGPT — Release Notes
- 4Get to know the new Google Home Speaker
- 5zai-org/GLM-5.2
- 6Improving health intelligence in ChatGPT
- 7New usage analytics and updated spend controls for enterprises
- 8Gemini 3.5 Flash
- 9模型上下架与更新 - 阿里云帮助中心
- 10阿里云百炼模型价格
围绕这条内容继续补充观点或上下文。